Converting a PDF to Excel from a URL is easy with our PDFTables API. Looking to extract information from a PDF you found online? Using our API and the script below, you can convert PDF to Excel, CSV, XML or HTML directly from a URL.
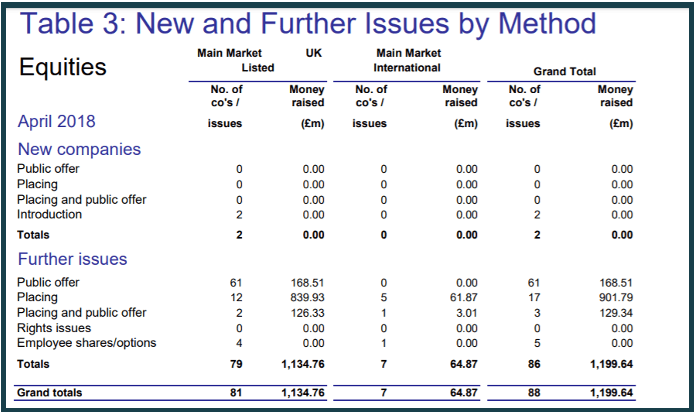
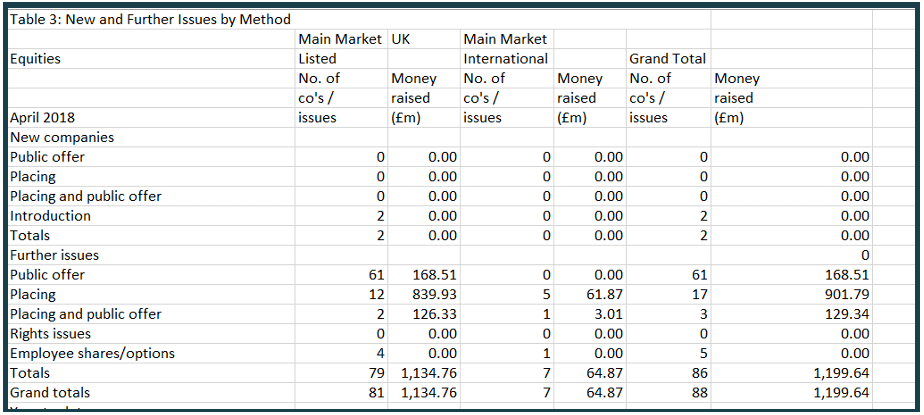
As an example we’ll be converting the London Stock Exchange’s April 2018 Main Market Factsheet. We’ll convert all 15 pages into a multi-sheet Excel workbook - an extract from page 5 is shown below. We'll be calling our API from Python using Windows.
Before we start
If you don't have Python installed on your computer, follow steps 1 and 2 of blog post Convert PDF to Excel, CSV or XML with Python. You will now have Python, Anaconda and the PDFTables Python library installed.
Step 1
Create a new file in the location where you'd like your converted PDF to be saved. Make sure the file is saved as .py format - use a file name of your choice. Add the following code to the new file:
#Import necessary Python modules
import requests
import pdftables_api
#Ask user to enter the URL where the PDF is located
url = input("Please enter URL: ")
print("converting...")
#The requests.get() method will retrieve the PDF file content from the URL defined above
mypdf = requests.get(url)
#Extracting the file name from the URL
mypdfname = url.split('/')[url.count("/")].split('.')[0]
#Creating a PDF file with the file name extracted above, then using the write function to enter the content of the PDF into the new file
with open(mypdfname+'.pdf', 'wb') as f:
f.write(mypdf.content)
#Define your unique PDFTables API key
c = pdftables_api.Client('my-api-key')
#Send request to PDFTables to convert and download your PDF to .xlsx format
c.xlsx(mypdfname+'.pdf', mypdfname)
print("PDF successfully converted")
You will need to make the following changes to the script:
- Replace
my-api-keyin line 17 with your API key which you will find here. - To convert to CSV, XML or HTML simply change
c.xlsxto bec.csv,c.xmlorc.htmlrespectively.
Step 2
Open up an Anaconda Prompt instance. You can find this by searching in your Windows search box. Press Enter to open an instance.
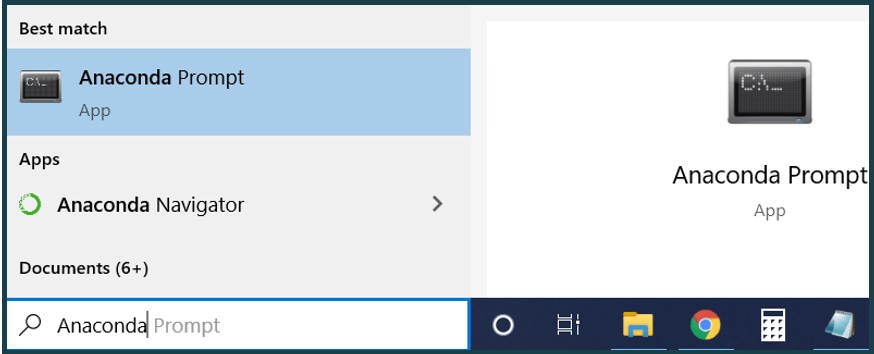
Locate the folder in which the Python script is saved using cd.. or cd *folder_name* to move around the directories.
Step 3
Type python convert_pdf_from_url.py (replacing convert_pdf_from_url.py with the name of your Python file). Press Enter and you will be asked to the enter a URL. Paste the URL into the terminal
by right-clicking.
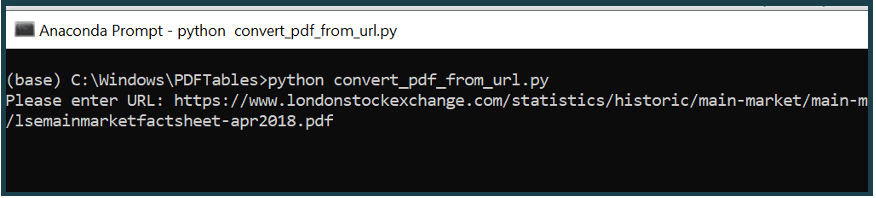
Press Enter again. Now the PDF will be downloaded and written to a PDF file in your folder. Next, a request will be sent to the PDFTables API to convert the PDF to .xlsx format. Finally, the converted PDF
will be downloaded into your folder. You will see the message PDF successfully converted once the script has finished running.
Step 4
You will now see an Excel file with the same name as the PDF in your folder. Open this Excel file and there will be a worksheet for each page of the converted PDF.
Do you have more questions?
Check out our other blog posts here or our FAQ page. Also, feel free to contact us.
Love PDFTables? Leave us a review on our Trustpilot page!