
Changes to the PDFTables.com free trial
An explanation of why the existing PDFTables.com free trial is ending
An explanation of why the existing PDFTables.com free trial is ending
A tutorial explaining how to convert a PDF invoice to a machine readable format like Excel with PDFTables.com
A case study explaining how the Carr Group converts financial statements from PDF to CSV and Excel spreadsheets with PDFTables.com

A case study explaining how the Carr Group converts delivery forms from PDF to CSV with PDFTables.com

An explanation of the importance of earliest return date in logistics

How we're trying to improve our sustainability

An explanation of the uses of PDFs in industries that use big data

An explanation of the uses of data in the logistics and transportation industries

An explanation of what HIPAA health documents are.
We show you how to convert a bank statement to Microsoft Excel format.

Some advantages of PDF documents over other formats.
Learn how to save a webpage as PDF for offline reading.
Learn how to change the delimiter in a CSV file from comma to semicolon or other using Python.

World Health Organization COVID-2019 situation reports available to download in Excel & CSV formats.
Learn how to convert your PDF to Excel directly from a website.
Learn how to convert your PDF then upload it to Google Drive using our API.
We show you how you could generate $000s from robotic process automation.
Learn how to convert your PDF to Excel using PDFTables.
Learn how to convert your PDF with the PDFTables API using R.

Our Product Manager gives an insight into living the digital nomad life in Spain!
Learn how to convert your PDFs to HTML with PDFTables.
Learn how to extract your PDF form data to Excel.
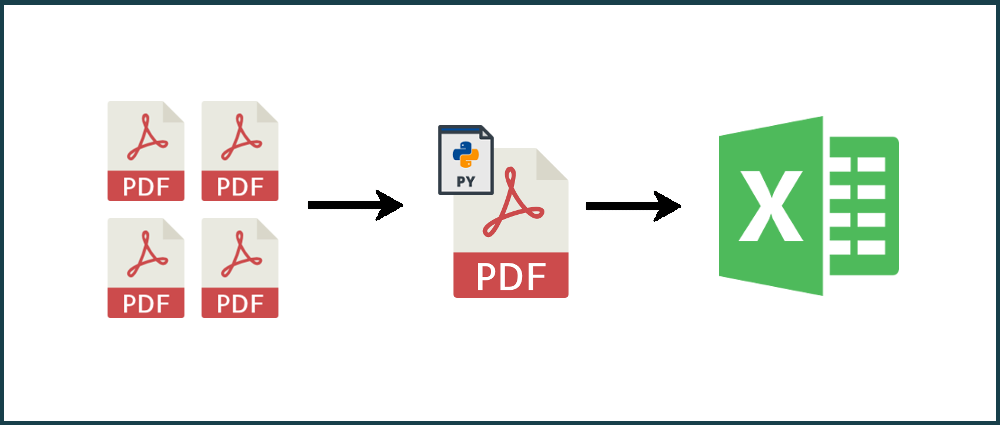
Learn how to merge PDF Files then convert specific pages to Excel with Python.
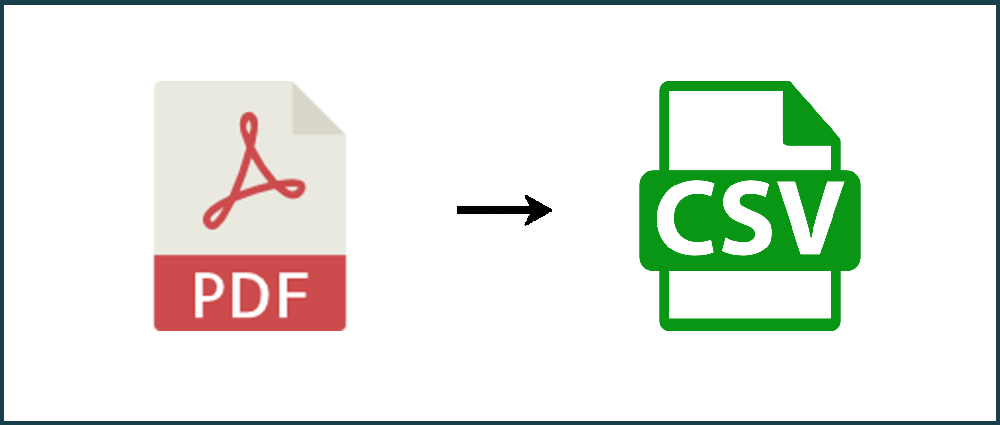
Learn how to convert PDF to CSV with PDFTables.
We talk you through microservices architecture and how PDFTables can be deployed as a microservice.
We've pulled together our 10 favourite Excel shortcuts, making Excel do more of the work for you!

Find out about the new release of PDFTables on-premises - helping businesses in their digital transformation.

The popularity of PDFs is ever-increasing. Learn about these trends and why we still use PDF today!
Use PDFTables as a PDF to XML converter. Follow these 5 simple steps.

We find out how our PDF to Excel API can save time in the health industry. We will sign a HIPAA BAA.

Downhill skiing, that is. An insight into my first month of remote working from France.
Learn how to convert a password protected PDF to Excel in 5 simple steps.
Learn how PDFTables can be used as a batch PDF converter using our API.
Learn how to convert a PDF bank statement to Excel or CSV and how to use a macro to merge multiple workbooks.
Learn how to convert a PDF to contacts vCard for Apple Mail, Outlook, Gmail, iOS and Android contacts.
Learn how to convert a balance sheet from PDF to Excel.
Learn how to extract pages from a PDF document with Google Chrome.
Learn how to use Python to convert specific pages from a PDF to Excel.
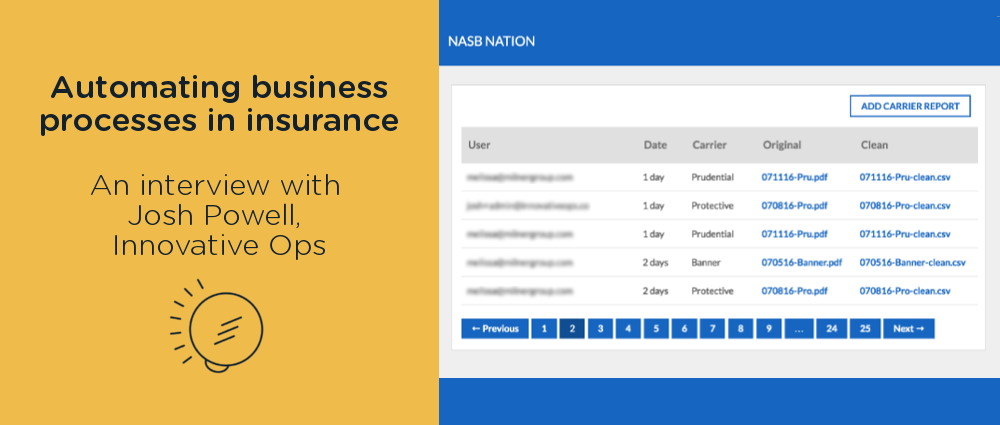
We find out how process automation is being achieved in the insurance sector with our PDF to Excel API.

What are blockchains, and what roles do they play in FinTech and InsurTech?

Easily integrate our PDF to Excel API into your applications with the PDFTables libraries. Use Python, R, Java, C# and more.
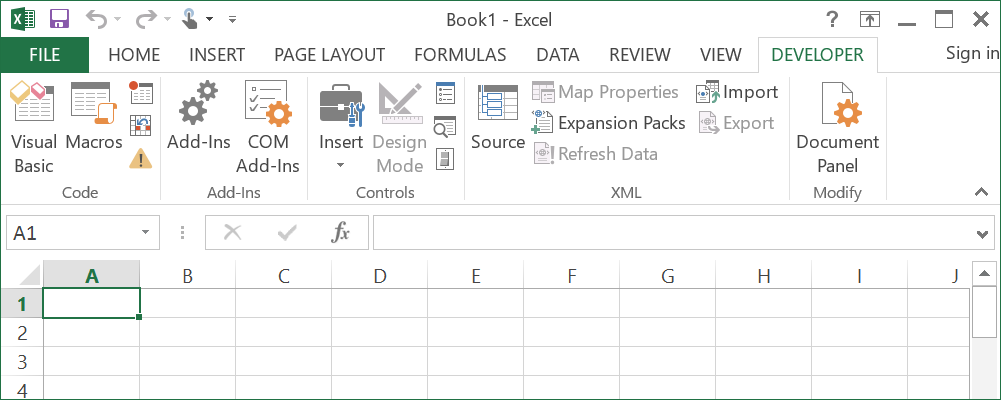
Learn how to activate the Excel Developer tab so you can start developing with VBA in Excel.

Learn how to use Python to convert a PDF to CSV or Excel on your desktop with the PDFTables API.

Find out how Milner Group Insurance brokerage automates their document processes with our API.

Find out how we've used customer feedback to improve our PDF to Excel conversion algorithm.

PDFs are being used and searched for more every year. We find out why.
Henry Morris uses PDFTables to get contacts from event delegate PDFs into his phone.