Updated February 2019
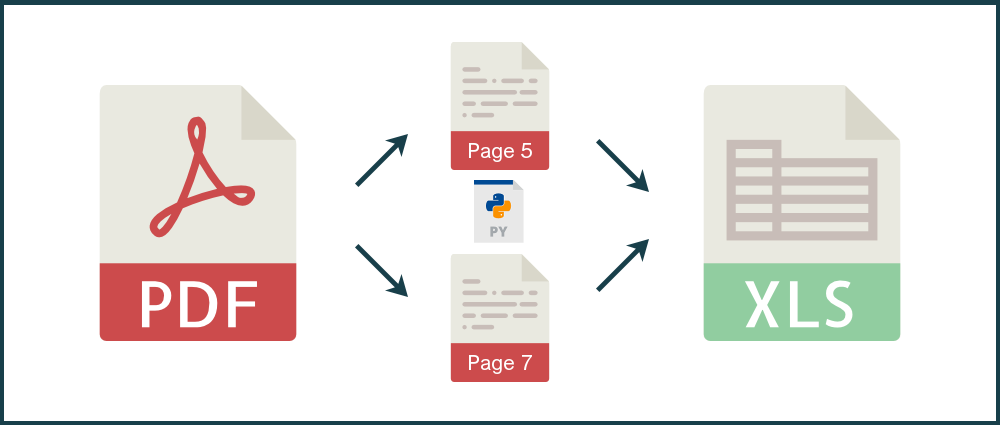
In this tutorial, I’ll be showing you how to use Python to convert specific pages of PDF tables into Excel, with the PDF to Excel API.
As an example we’ll be using the London Stock Exchange’s June 2017 Main Market Factsheet. We’ll extract and convert pages 5 (New and Further Issues by Method) and 7 (Money Raised by Business Sector) into a multi-sheet Excel workbook.
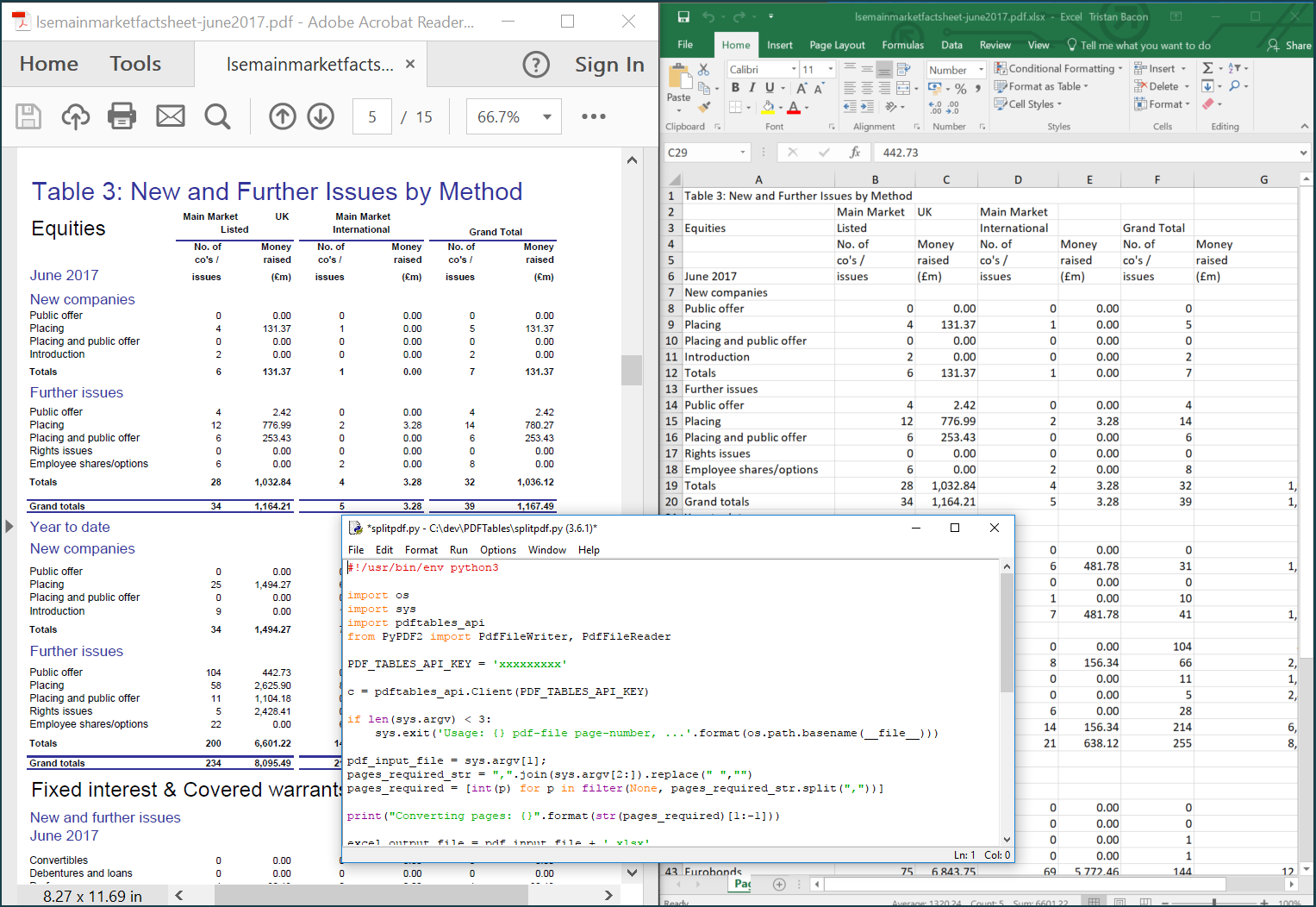
Here's what the end result will look like with the example PDF.
Before we start
In the previous tutorial (How to convert a PDF to Excel with Python), I showed you how to get the PDFTables Python library set up and running on your machine. If you haven’t already set up the library, I’d recommend reading that tutorial first.
Additionally, you'll need an API key and the PyPDF2 library installed, which you can do via the command line/terminal with the following command:
pip install pypdf2
Step 1
Create a new Python script then add the following code:
#!/usr/bin/env python3
import os
import sys
import pdftables_api
from PyPDF2 import PdfFileWriter, PdfFileReader
if len(sys.argv) < 3:
command = os.path.basename(__file__)
sys.exit('Usage: {} pdf-file page-number, ...'.format(command))
pdf_input_file = sys.argv[1];
pages_args = ",".join(sys.argv[2:]).replace(" ","")
pages_required = [int(p) for p in filter(None, pages_args.split(","))]
print("Converting pages: {}".format(str(pages_required)[1:-1]))
excel_output_file = pdf_input_file + '.xlsx'
pages_out_of_range = []
pdf_file_reader = PdfFileReader(open(pdf_input_file, 'rb'))
pdf_file_pages = pdf_file_reader.getNumPages()
for page_number in pages_required:
if page_number < 1 or page_number > pdf_file_pages:
pages_out_of_range.append(page_number)
if len(pages_out_of_range) > 0:
pages_str = str(pages_out_of_range)[1:-1]
sys.exit('Error: page numbers out of range: {}'.format(pages_str))
pdf_writer_selected_pages = PdfFileWriter()
for page_number in pages_required:
page = pdf_file_reader.getPage(page_number-1)
pdf_writer_selected_pages.addPage(page)
pdf_file_selected_pages = pdf_input_file + '.tmp'
with open(pdf_file_selected_pages, 'wb') as f:
pdf_writer_selected_pages.write(f)
c = pdftables_api.Client('my-api-key')
c.xlsx(pdf_file_selected_pages, excel_output_file) #use c.xlsx_single here to output all pages to a single Excel sheet
print("Complete")
os.remove(pdf_file_selected_pages)
Step 2
Replace my-api-key on line #43 with your PDFTables API key, which you
can get from
our PDF to Excel API page. Save your finished script as convertpdfpages.py in the same directory as the PDF document you want to convert.
Step 3
Navigate to your convertpdfpages.py file in the command line/terminal and run the following:
python convertpdfpages.py lsemainmarketfactsheet-june2017.pdf 5,7
The script will then print the following:
Converting pages: 5, 7 Complete
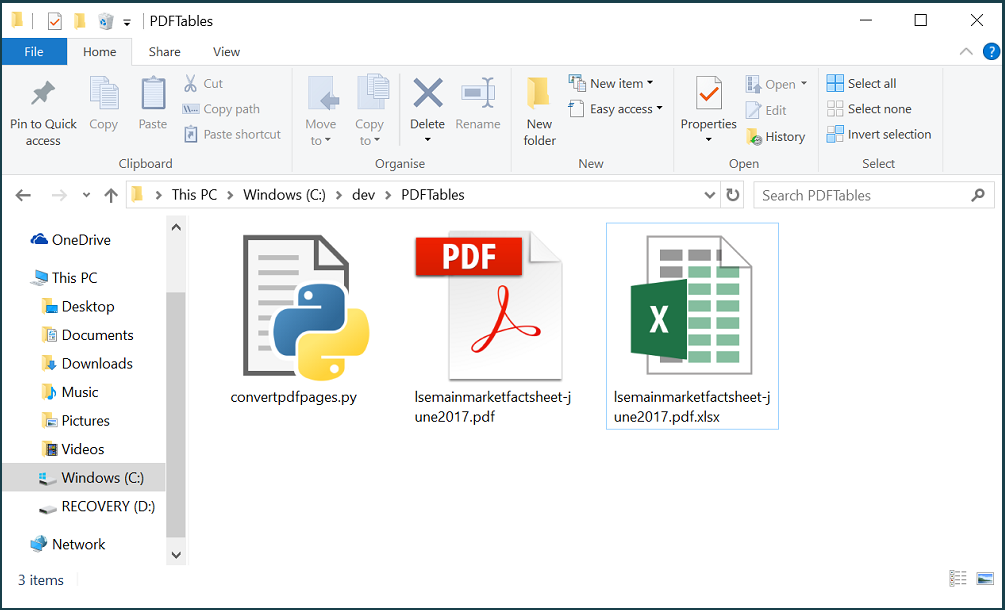
This means that the conversion was successful. You’ll find your output XLSX in the same folder as the script and example PDF.
If you open the XLSX now, you’ll see that pages 5 and 7 have been converted and added to their own sheets!
You're all done! You have successfully converted specific PDF pages to Excel using Python.
To convert to CSV, XML or HTML simply change c.xlsx to be c.csv,
c.xml or c.htmlrespectively.
Do you have more questions?
Check out our other blog posts here or our FAQ page. Also, feel free to contact us.