
We continue to improve the algorithm that analyzes and retrieves content from your PDFs. We've recently implemented some larger updates to our algorithm and thought this would be a good opportunity to show you some of our work!
Let's consider some examples - we'll start with what we internally call a shipping-manifest-type PDF.
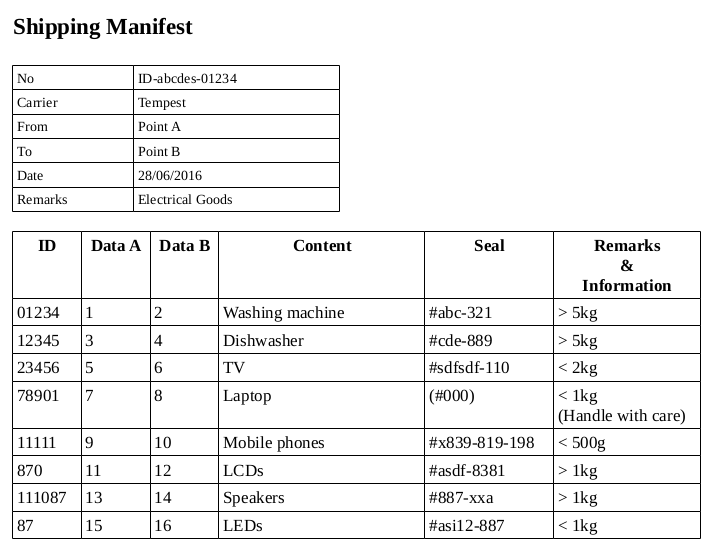
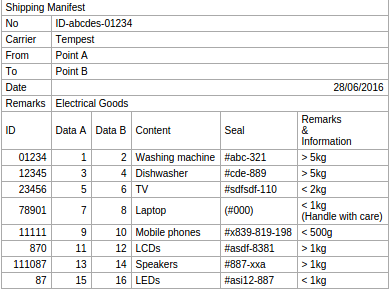
Customers approach us frequently with this type of document (in all its variations!) and give us feedback on how the conversion went. Having access to customer PDFs enables us to fine-tune our algorithm which results in an improvement for the customer. We make changes to the PDFTables algorithm with one aim only: to minimize the time you have to spend on post-processing the extracted data!
If you'd like to find out whether we can improve the content extraction for your PDF files, get in touch at hello@pdftables.com. Please don't forget to attach the relevant PDFs!
Next let's answer the question you've probably been dying to ask:
How hard can it be to extract data from PDFs?
PDF files contain only the most basic information necessary to display their content. Most of the time, all we have to work with is a series of simple graphical instructions such as drawing a character at point, or drawing a line from point A to point B. PDFs generally do not contain higher-level data structures such as tables. While humans can easily recognize such structures visually, it is quite a different thing to teach a computer to perform this task. This is where PDFTables comes in - our algorithm analyzes the spatial information contained in a PDF to construct tables!
Consider this fairly straight-forward example:
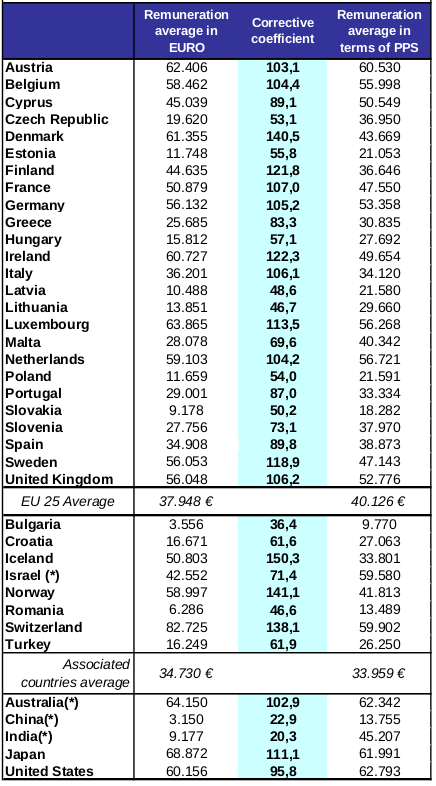
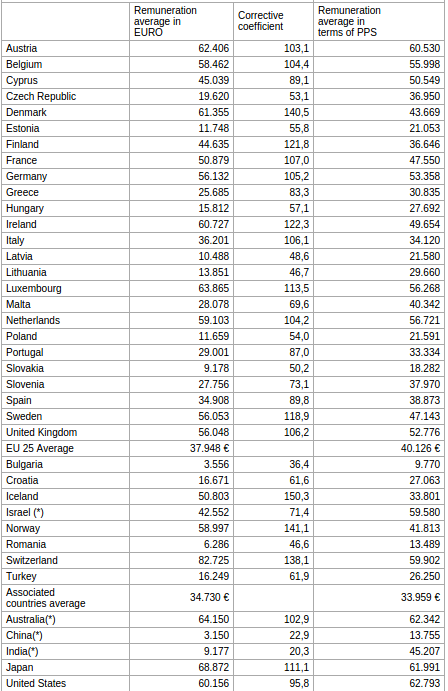
PDFTables did a great job recognizing the column header containing multiple lines of text. This is one of the improvements we've recently made: using the line information to deduce whether multiple lines of text belong in one cell.
The above table had a clear structure so let's next take a look at one that might be not as obvious:
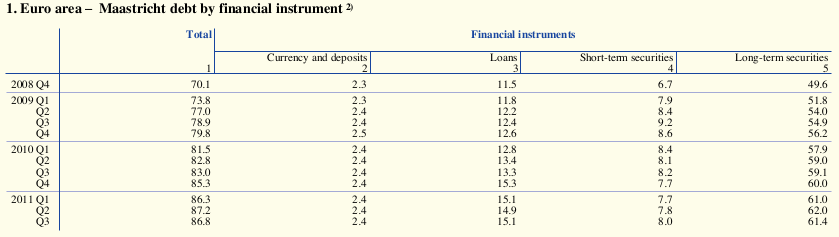
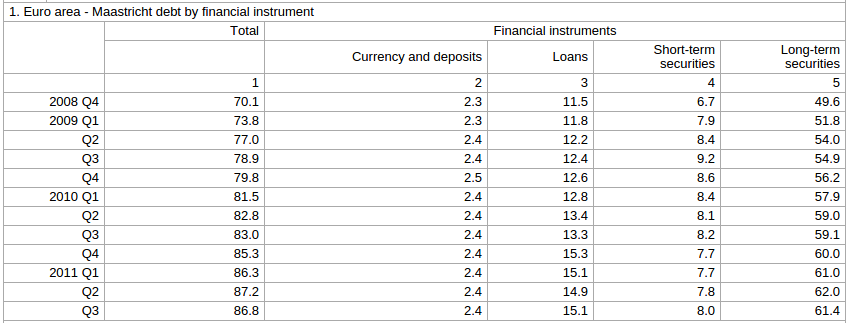
That's why it is important that you sent us any PDF that you'd like to see improved!Every additional PDF helps us to improve our system and to find edge cases. I hope we've given you some small insights in what makes PDFTables work, as well as hinted at some of the work that's still ahead of us.
Got a PDF for which PDFTables returns an output that you'd like to see improved? Get in touch at hello@pdftables.com or on Twitter.