Updated July 2019
You can batch convert PDF to Excel using the PDFTables API. If, like me, you'd like to automate your processes or need a quick and easy way to convert multiple PDFs at once, this is the tutorial for you. I will show you how to use PDFTables as a batch PDF to Excel converter using our API.
I'll be calling our API from Python, using a Mac (the instructions are very similar for Windows and Linux). The API is very useful for integrating PDF extraction into your operations. You'll easily be able to import data from PDF files into your database.
Before we start
I will be converting a sample PDF bank statement from JPMorgan Chase and a set of pages from a PDF version of Nestlé Group's Consolidated Financial Statements for 2016. If you would like to convert only specific pages from a PDF, see our tutorial on how to convert specific PDF pages to Excel with Python.
Step 1
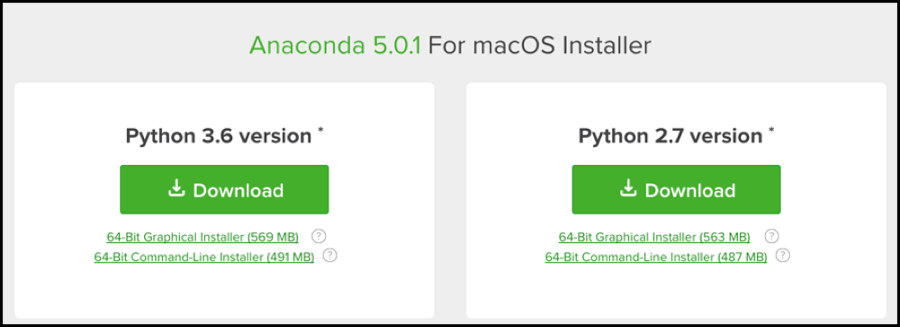
Download Anaconda by choosing the MacOS option and selecting the Python 3.6 version. This can take a little while to download so now is a good time to grab a cup of tea! 🍵
Step 2
Once the download is complete, click the downloaded package and run through the installation window that pops up. This may also take a little while! Close when all is finished. To check it has installed, go to 'Finder' and click 'Applications' and you will see Anaconda in the list (for Windows, in Explorer, go to your C drive and search for 'Anaconda'). Downloading Anaconda means that pip will also be installed. Pip gives a simple way to install the PDFTables API Python package.
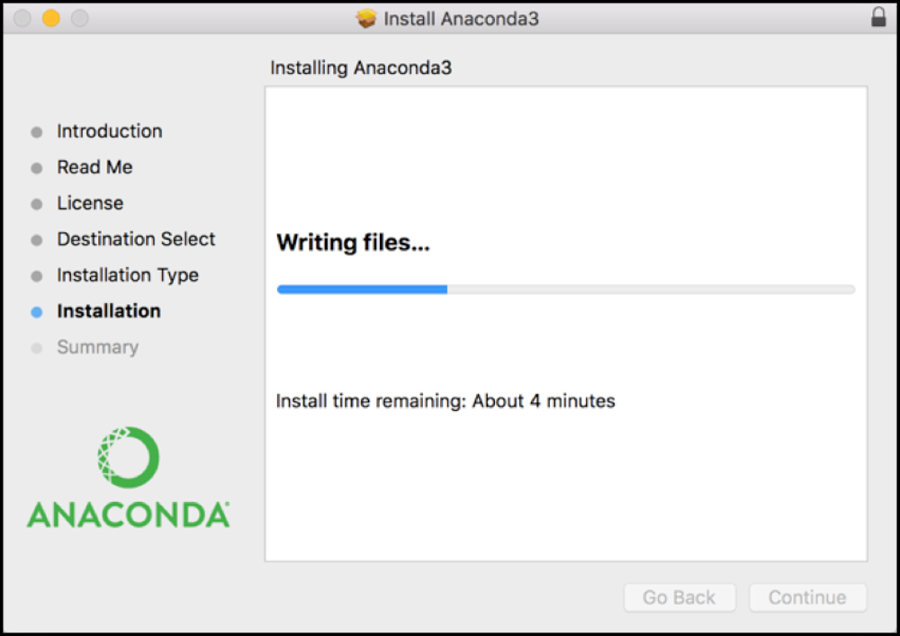
Step 3
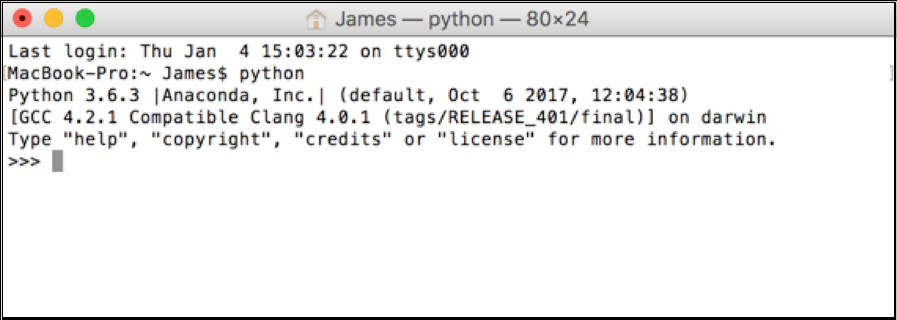
Press F4 on your keyboard to open up apps. Type 'terminal' and click the black
box logo that appears (For Windows, search for Anaconda Prompt in the Start Menu
and run it). To check Python is working, type python and then the return key.
If it looks similar to the image below, you are all set up. If not, try uninstalling
Anaconda and installing it again.
Step 4
Next, if you haven't already, you will need to create an account on PDFTables to enable you to call the API. Click 'Join' in the header of any page on our website to sign up for free. An activation link will arrive in your email inbox which you will need to click.
Step 5
Open up the Terminal again, press Ctrl+Z to exit Python (For Windows, type exit()
and hit return). Run the following command to clone the PDFTables API from
Github:
pip install git+https://github.com/pdftables/python-pdftables-api.git
If git is not recognised, download it here. Then, run the above command again.
Step 6
You will need a code editor to create a Python script. If you don't already have one, I'd recommend Bbedit for a Mac, Notepad++ for Windows or Atom for Linux.
Step 7
Once the code editor has downloaded, open it up and create a new blank page. Copy the following code onto the page:
import pdftables_api
import os
c = pdftables_api.Client('MY-API-KEY')
file_path = "C:\\Users\\MyName\\Documents\\PDFTablesCode\\"
for file in os.listdir(file_path):
if file.endswith(".pdf"):
c.xlsx(os.path.join(file_path,file), file+'.xlsx')
You will need to make the following changes to the script:
- Replace
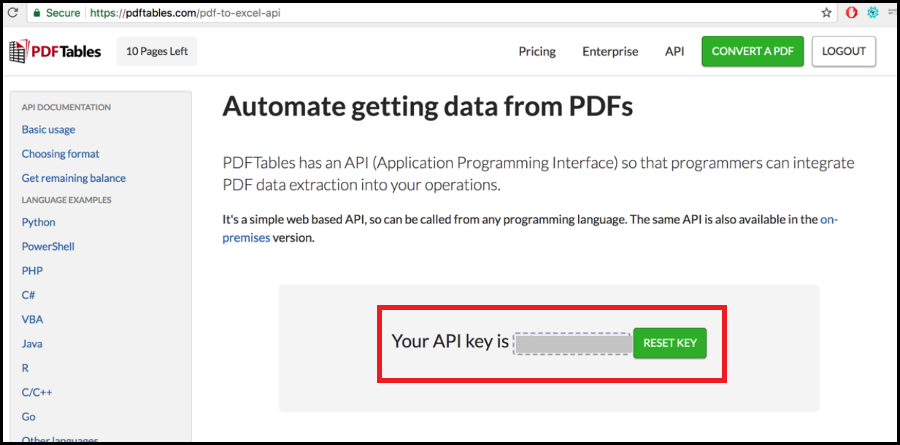
MY-API-KEYwith your PDFTables API key which you will find here. - Replace
C:\\Users\\MyName\\Documents\\PDFTablesCode\\with the path to where your PDF documents are saved. If you are copying the path in Windows, replace the single '\' with '\\' or '/'. - To convert to CSV, XML or HTML simply change
c.xlsxto bec.csv,c.xmlorc.htmlrespectively.
Step 8
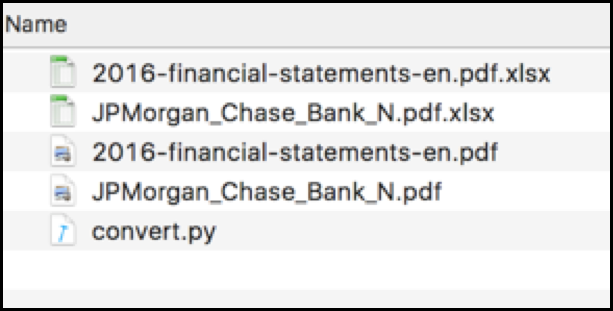
Save the Python script as 'convert.py' in the same folder as the PDF documents.
Step 9
Go back to the Terminal (or Anaconda Prompt), locate the folder in which the Python script and PDFs are
saved using cd.. or cd *folder_name* to move around the directories.
Type python convert.py in the Terminal. Press enter and let this run. Once it has
finished, you will see an Excel file for each PDF document in the folder.
You now know how to batch convert your PDFs to Excel using our API!
Now that everything has been setup, just repeat steps 7, 8 & 9 to convert multiple PDFs again.
Do you have more questions?
Check out our other blog posts here or our FAQ page. Also, feel free to contact us.
Love PDFTables? Leave us a review on our Trustpilot page!